Visualisation de données avec pandas et matplotlib
Introduction de Pandas
La librairie pandas permet de manipuler de
façon performantes et facile des données structurées, par exemple sous forme
de tableau. Les objets disponnibles dans pandas permettent de trier, consolider,
compléter vos données et de les exporter dans divers format (csv, latex, excel ...)
Pour commencer avec Pandas, je vous recommande la lecture de cette introduction sur la documentation officielle :
et de cette description des divers objets de pandas :
Chargement des données à partir d'un fichier CSV
Les données proviennent de http://opendata.agglo-pau.fr/index.php/fiche?idQ=27
Lors du téléchargement de l'archive, le fichier csv contient les données et un fichiers excel décrit le contenu de chaque colonne.
Ici, le fichier csv est lu directement avec la fonction read_csv de pandas, en
précisant que le séparateur est un point virgule. Cette fonction retourne un
objet DataFrame qui s'apparente à un tableau de données. On précise également
que LIBGEO, le nom de la commune, sera utilisé comme index de la DataFrame
de pandas. Chaque ligne portera alors le nom de la ville correspondante.
import pandas as pd
df = pd.read_csv("Evolution_et_structure_de_la_population/Evolution_structure_population.csv", sep=";")
df = df.set_index("libgeo")
df
| ccodgeo | reg | dep | arr | cv | ze2010 | id_modif_geo | p11_pop | p99_pop | d90_pop | ... | c10_pop55p | c10_pop55p_cs1 | c10_pop55p_cs2 | c10_pop55p_cs3 | c10_pop55p_cs4 | c10_pop55p_cs5 | c10_pop55p_cs6 | c10_pop55p_cs7 | c10_pop55p_cs8 | evol99_11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| libgeo | |||||||||||||||||||||
| ARTIGUELOUTAN | 64059 | 72 | 64 | 643 | 6431 | 7214 | ZZZZZZ | 944 | 722.0 | 669 | ... | 256 | 8 | 4 | 8 | 12 | 16 | 12 | 180 | 16 | 30.747922 |
| BILLERE | 64129 | 72 | 64 | 643 | 6451 | 7214 | ZZZZZZ | 13343 | 13390.0 | 12570 | ... | 4245 | 9 | 47 | 188 | 185 | 289 | 101 | 3150 | 276 | -0.351008 |
| BIZANOS | 64132 | 72 | 64 | 643 | 6447 | 7214 | ZZZZZZ | 4773 | 4674.0 | 4298 | ... | 1754 | 0 | 40 | 124 | 80 | 52 | 44 | 1337 | 76 | 2.118100 |
| GAN | 64230 | 72 | 64 | 643 | 6446 | 7214 | ZZZZZZ | 5481 | 4961.0 | 4724 | ... | 1890 | 12 | 55 | 95 | 103 | 69 | 40 | 1411 | 106 | 10.481758 |
| GELOS | 64237 | 72 | 64 | 643 | 6448 | 7214 | ZZZZZZ | 3620 | 3665.0 | 3529 | ... | 1262 | 8 | 24 | 36 | 56 | 72 | 45 | 917 | 104 | -1.227831 |
| IDRON | 64269 | 72 | 64 | 643 | 6431 | 7214 | ZZZZZZ | 4091 | 5151.0 | 2311 | ... | 1144 | 0 | 38 | 100 | 96 | 59 | 13 | 763 | 75 | -20.578528 |
| JURANCON | 64284 | 72 | 64 | 643 | 6446 | 7214 | ZZZZZZ | 7037 | 7381.0 | 7538 | ... | 2494 | 0 | 44 | 104 | 164 | 124 | 96 | 1744 | 217 | -4.660615 |
| LEE | 64329 | 72 | 64 | 643 | 6431 | 7214 | ZZZZZZ | 1213 | 779.0 | 446 | ... | 300 | 0 | 4 | 51 | 16 | 8 | 4 | 199 | 20 | 55.712452 |
| LESCAR | 64335 | 72 | 64 | 643 | 6419 | 7214 | ZZZZZZ | 10030 | 8191.0 | 5793 | ... | 2733 | 12 | 54 | 207 | 120 | 107 | 87 | 1912 | 233 | 22.451471 |
| LONS | 64348 | 72 | 64 | 643 | 6419 | 7214 | ZZZZZZ | 12304 | 11153.0 | 9254 | ... | 3696 | 9 | 62 | 183 | 171 | 249 | 146 | 2603 | 273 | 10.320093 |
| MAZERES-LEZONS | 64373 | 72 | 64 | 643 | 6448 | 7214 | ZZZZZZ | 1921 | 2143.0 | 2079 | ... | 743 | 8 | 4 | 20 | 12 | 41 | 9 | 597 | 53 | -10.359309 |
| OUSSE | 64439 | 72 | 64 | 643 | 6431 | 7214 | ZZZZZZ | 1554 | NaN | 937 | ... | 388 | 0 | 17 | 44 | 17 | 22 | 0 | 253 | 35 | NaN |
| PAU | 64445 | 72 | 64 | 643 | 6499 | 7214 | ZZZZZZ | 79798 | 78800.0 | 82157 | ... | 26112 | 9 | 383 | 1078 | 1155 | 1535 | 752 | 18870 | 2330 | 1.266497 |
| SENDETS | 64518 | 72 | 64 | 643 | 6423 | 7214 | ZZZZZZ | 873 | NaN | 640 | ... | 256 | 0 | 0 | 24 | 8 | 16 | 4 | 199 | 4 | NaN |
14 rows × 148 columns
4 exemples de graphiques
Dans cette section sera présenté la construction de 4 graphiques en utilisant
matplotlib comme librairie graphique et pandas pour
manipuler les données.
Les données utilisées dans cet exemple sont issues de la base de données ouverte de la Communauté d'Agglomération de Pau-Pyrénées (CAPP) opendata.agglo-pau.fr. La section précédente présente comment lire ces données avec pandas.
Ce document peut être consulté sous forme de notebook.
Nous allons réaliser les 4 graphiques suivants. Avant de lire la suite, vous pouvez essayer de reproduire vous même ces graphiques :
- Un graphique simple de type xy
- Représenter le nombre de naissance et de décés à Pau en fonction du temps
- (Sup) ajouter une courbe de tendance linéaire.
- Un diagramme en barres horizontales
- Chaque barre représente la population d'une commune en 2011
- La colonne du tableau est
P11_POP - Les communes seront classées par ordre croissant de population.
- Une treemap sous forme de rectangle avec
squarify:- L'aire de chaque rectangle correspond à la superficie de la commune
- L'échelle de couleur correspond à la population de la commune
- La population de Pau n'est pas prise en compte pour ne pas écraser l'échelle
- Chaque rectangle est annoté par la superficie et la population.
- Un diagramme camembert (ou pie chart)
- Représenter la répartition en catégories socio-professionnelles pour Pau et la CAPP
- Représenter la répartition en catégories socio-professionnelles pour Billère et la CAPP
Commençons par importer les modules python nécessaires :
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
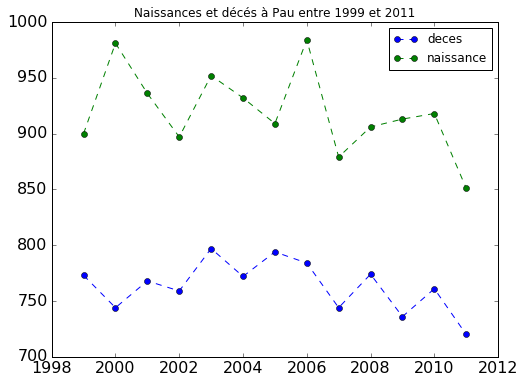
1. Graphique xy classique
Dans ce graphique nous allons simplement représenter le nombre de naissances et
de décés à Pau entre 1999 et 2011. C'est un graphique très simple à réaliser
avec pandas. Nous allons voir tout d'abord comment extraire les données puis
nous ferons un premier graphique basique avec la fonction plot() de pandas.
Ensuite, nous ajouterons une courbe de tendance linéaire avec
lineregress()
de scipy.
Tout d'abord nous devons extraire les colonnes NAISXX et DECEXX du tableau
global pour la ligne concernant Pau.
# noms des colonnes:
years = [99] + list(range(0, 12))
naissance = ["nais%02d" % y for y in years]
deces = ["dece%02d" % y for y in years]
# extraction de la ligne qui concerne Pau
df_pau = df[df.index == "PAU"].squeeze()
# nouvelle DataFrame avec les deces et les naissances à Pau en fonction des années
dfxy = pd.DataFrame(
data={
"naissance": df_pau[naissance].values,
"deces": df_pau[deces].values
},
index=[1999 + i for i in range(0, 13)]
)
dfxy
| deces | naissance | |
|---|---|---|
| 1999 | 773 | 900 |
| 2000 | 744 | 981 |
| 2001 | 768 | 936 |
| 2002 | 759 | 897 |
| 2003 | 797 | 952 |
| 2004 | 772 | 932 |
| 2005 | 794 | 909 |
| 2006 | 784 | 984 |
| 2007 | 744 | 879 |
| 2008 | 774 | 906 |
| 2009 | 736 | 913 |
| 2010 | 761 | 918 |
| 2011 | 720 | 851 |
À partir de ce type de tableau, il est très simple de tracer des courbes avec la
fonction plot() de pandas. Les arguments sont du même type que ceux de
matplotlib :
dfxy.plot(
marker="o",
linestyle="dashed",
title="Naissances et décés à Pau entre 1999 et 2011",
figsize=(8, 6),
fontsize=16,
xlim=(1998, 2012)
)
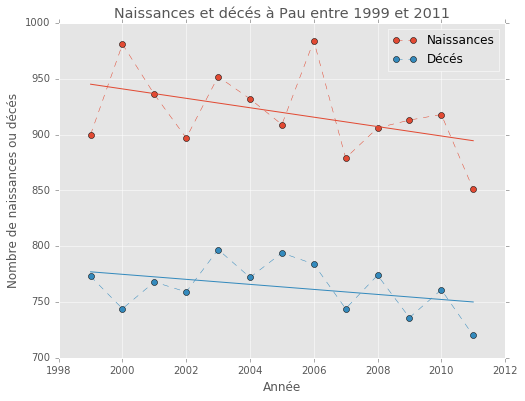
Ajoutons maintenant une courbe de tendance et ajoutons les données au tableau (bien que deux points seulement auraient suffit) :
from scipy.stats import linregress
# pour les naissances
p_naissance, i_naissance, *others = linregress(x=dfxy.index, y=dfxy.naissance)
dfxy["trend_naissance"] = p_naissance * dfxy.index + i_naissance
# pour les décés
p_deces, i_deces, *others = linregress(x=dfxy.index, y=dfxy.deces)
dfxy["trend_deces"] = p_deces * dfxy.index + i_deces
| deces | naissance | trend_naissance | trend_deces | |
|---|---|---|---|---|
| 1999 | 773 | 900 | 945.164835 | 777.054945 |
| 2000 | 744 | 981 | 940.945055 | 774.802198 |
| 2001 | 768 | 936 | 936.725275 | 772.549451 |
| 2002 | 759 | 897 | 932.505495 | 770.296703 |
| 2003 | 797 | 952 | 928.285714 | 768.043956 |
| 2004 | 772 | 932 | 924.065934 | 765.791209 |
| 2005 | 794 | 909 | 919.846154 | 763.538462 |
| 2006 | 784 | 984 | 915.626374 | 761.285714 |
| 2007 | 744 | 879 | 911.406593 | 759.032967 |
| 2008 | 774 | 906 | 907.186813 | 756.780220 |
| 2009 | 736 | 913 | 902.967033 | 754.527473 |
| 2010 | 761 | 918 | 898.747253 | 752.274725 |
| 2011 | 720 | 851 | 894.527473 | 750.021978 |
plt.style.use('ggplot')
# figure
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111)
ax.set_title("Naissances et décés à Pau entre 1999 et 2011", color="#555555")
# plot the differents quantities
ax.plot(dfxy.index, dfxy.naissance, marker="o", label="Naissances", linestyle="--", linewidth=.5)
ax.plot(dfxy.index, dfxy.deces, marker="o", label="Décés", linestyle="--", linewidth=.5)
ax.plot(dfxy.index, dfxy.trend_naissance, label="", color="#E24A33")
ax.plot(dfxy.index, dfxy.trend_deces, label="", color="#348ABD")
# format and style
ax.set_xlabel("Année")
ax.set_ylabel("Nombre de naissances ou décés")
ax.legend()
fig.savefig("xy_pop.png", dpi=300)
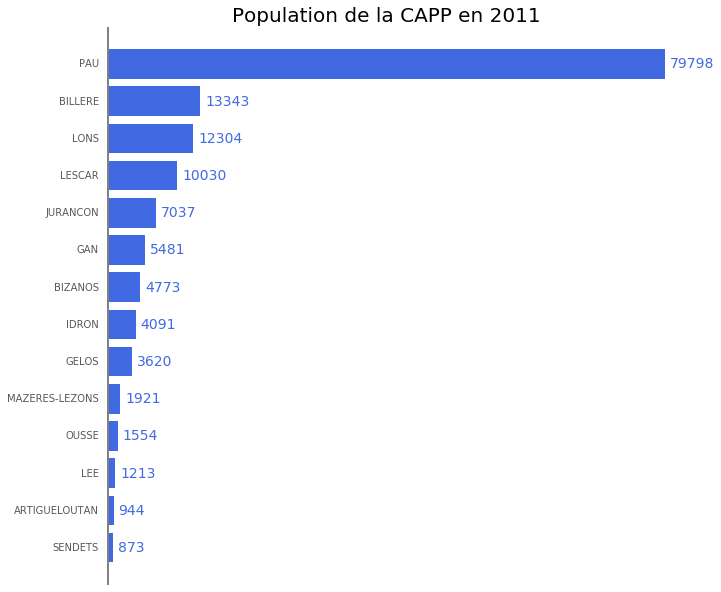
2. Un diagramme en barres
Premièrement nous allons construire un graphique sous forme de barres horizontales, représentant la population dans chaque ville de l'aglomération de Pau-Pyrénées en 2011.
Nous utiliserons un diagramme en barre horizontale avec la fonction barh de
matplotlib (exemple).
Commençons par extraire la colonne qui nous intéresse (P11_POP) et classons
les valeurs par ordre croissant.
pop11 = df["p11_pop"]
pop11 = pop11.sort_values(ascending=True)
pop11
libgeo
SENDETS 873
ARTIGUELOUTAN 944
LEE 1213
OUSSE 1554
MAZERES-LEZONS 1921
GELOS 3620
IDRON 4091
BIZANOS 4773
GAN 5481
JURANCON 7037
LESCAR 10030
LONS 12304
BILLERE 13343
PAU 79798
Name: p11_pop, dtype: int64
Construisons maintenant le graphique avec les données ci-dessus.
# figure
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111)
ax.set_title("Population de la CAPP en 2011", fontsize=20)
# bar plot
ax.barh(
# position et longueur des barres
bottom=range(pop11.count()),
width=pop11,
# labels
align="center",
tick_label=pop11.index,
# couleurs et traits
color="RoyalBlue",
linewidth=0
)
# format axis
ax.set_frame_on(False)
ax.set_xticks([])
ax.tick_params("both", length=0)
ax.vlines(0, -1, pop11.count(), color="gray", linewidth=4)
# add the value at the end of the bar
for y, pop in enumerate(pop11):
ax.annotate(
# texte
"%.0f" % pop,
# position
xy=(pop, y),
xytext=(5, -4),
textcoords="offset points",
# format
fontsize=14,
color="RoyalBlue"
)
fig.savefig("barh_pop.png", dpi=300)
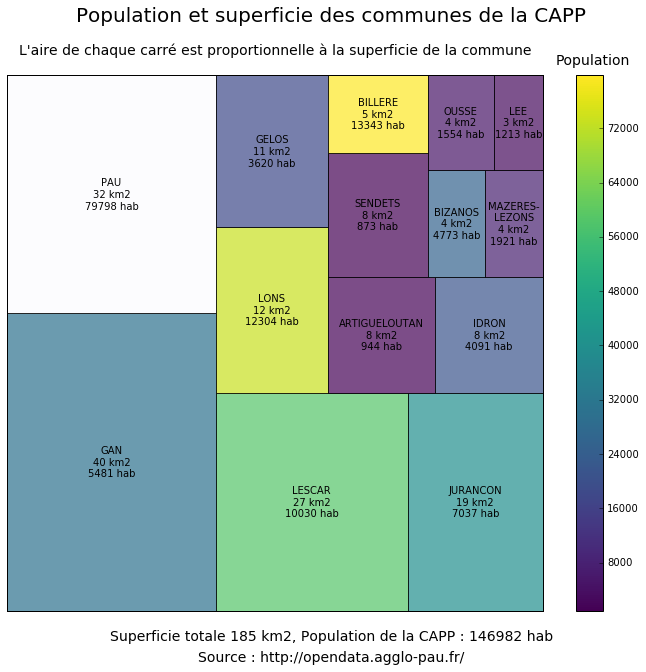
3. Réalisation d'une Treemap
Pour faire ce graphique on va utiliser la librairie
squarify. La superficie
des rectangles représentera la superficie de la commune. Une échelle de couleur
donnera la population de la commune.
import squarify
Extraction de la superficie des communes et de la population en 2011. Le tableau est trié par ordre décroissant de la superficie.
df2 = df[["superf", "p11_pop"]]
df2 = df2.sort_values(by="superf", ascending=False)
df2
| superf | p11_pop | |
|---|---|---|
| libgeo | ||
| GAN | 40 | 5481 |
| PAU | 32 | 79798 |
| LESCAR | 27 | 10030 |
| JURANCON | 19 | 7037 |
| LONS | 12 | 12304 |
| GELOS | 11 | 3620 |
| ARTIGUELOUTAN | 8 | 944 |
| IDRON | 8 | 4091 |
| SENDETS | 8 | 873 |
| BILLERE | 5 | 13343 |
| BIZANOS | 4 | 4773 |
| MAZERES-LEZONS | 4 | 1921 |
| OUSSE | 4 | 1554 |
| LEE | 3 | 1213 |
Superficie et population de Pau :
print("Pau: superficie = %d km2, population = %d\n" % (df2["superf"]["PAU"], df2["p11_pop"]["PAU"]))
Pau: superficie = 32 km2, population = 79798
Représentation en Treemaps avec les fonctions inclues dans
squarify.
x = 0.
y = 0.
width = 100.
height = 100.
cmap = matplotlib.cm.viridis
# color scale on the population
# min and max values without Pau
mini, maxi = df2.drop("PAU").p11_pop.min(), df2.drop("PAU").p11_pop.max()
norm = matplotlib.colors.Normalize(vmin=mini, vmax=maxi)
colors = [cmap(norm(value)) for value in df2.p11_pop]
colors[1] = "#FBFCFE"
# labels for squares
labels = ["%s\n%d km2\n%d hab" % (label) for label in zip(df2.index, df2.superf, df2.p11_pop)]
labels[11] = "MAZERES-\nLEZONS\n%d km2\n%d hab" % (df2["superf"]["MAZERES-LEZONS"], df2["p11_pop"]["MAZERES-LEZONS"])
# make plot
fig = plt.figure(figsize=(12, 10))
fig.suptitle("Population et superficie des communes de la CAPP", fontsize=20)
ax = fig.add_subplot(111, aspect="equal")
ax = squarify.plot(df2.superf, color=colors, label=labels, ax=ax, alpha=.7)
ax.set_xticks([])
ax.set_yticks([])
ax.set_title("L'aire de chaque carré est proportionnelle à la superficie de la commune\n", fontsize=14)
# color bar
# create dummy invisible image with a color map
img = plt.imshow([df2.p11_pop], cmap=cmap)
img.set_visible(False)
fig.colorbar(img, orientation="vertical", shrink=.96)
fig.text(.76, .9, "Population", fontsize=14)
fig.text(.5, 0.1,
"Superficie totale %d km2, Population de la CAPP : %d hab" % (df2.superf.sum(), df2.p11_pop.sum()),
fontsize=14,
ha="center")
fig.text(.5, 0.07,
"Source : http://opendata.agglo-pau.fr/",
fontsize=14,
ha="center")
fig.savefig("treemap_capp_pau.png", dpi=300)
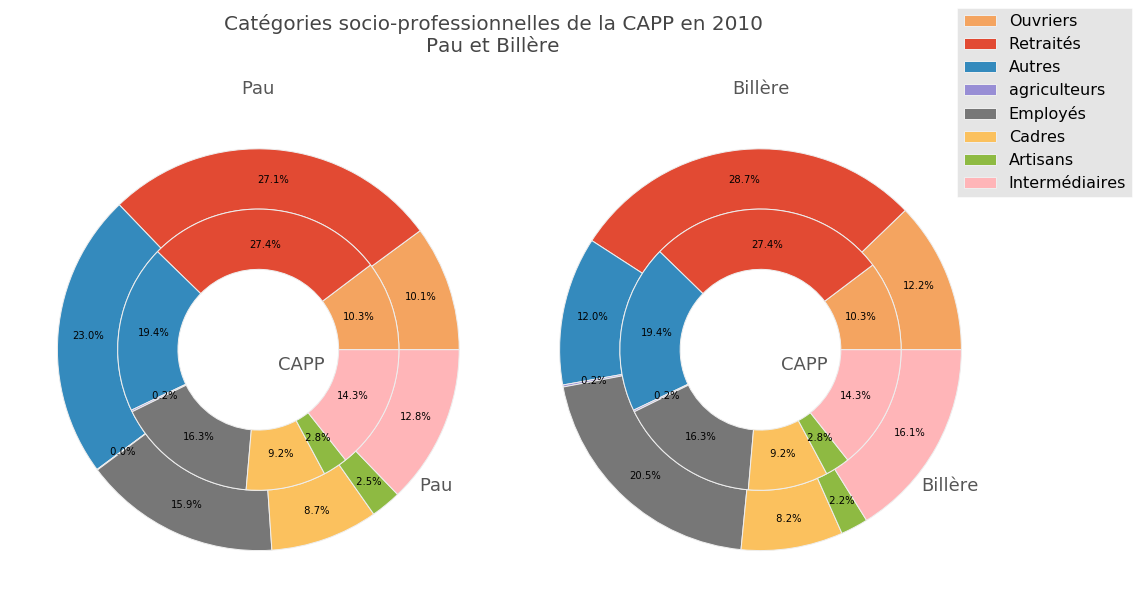
4. Camembert ou pie chart ou wedge chart
Le fichiers de données de la CAPP contient aussi les catégorie socio-professionnelle pour chaque commune. Nous allons les représenter avec un diagramme de type camembert.
Commençons par regrouper les données dans une nouvelle table et faisons la somme sur toutes les communes.
columns = {
"c10_pop15p_cs1": "agriculteurs",
"c10_pop15p_cs2": "Artisans",
"c10_pop15p_cs3": "Cadres",
"c10_pop15p_cs4": "Intermédiaires",
"c10_pop15p_cs5": "Employés",
"c10_pop15p_cs6": "Ouvriers",
"c10_pop15p_cs7": "Retraités",
"c10_pop15p_cs8": "Autres"
}
df_cat = df[list(columns.keys())]
df_cat = df_cat.rename(columns=columns)
# add the sum over CAPP
df_cat.loc["CAPP"] = df_cat.sum(axis=0)
df_cat["total"] = df_cat.sum(axis=1)
df_cat
| Ouvriers | Retraités | Autres | agriculteurs | Employés | Cadres | Artisans | Intermédiaires | total | |
|---|---|---|---|---|---|---|---|---|---|
| libgeo | |||||||||
| ARTIGUELOUTAN | 72 | 184 | 80 | 24 | 140 | 40 | 20 | 164 | 724 |
| BILLERE | 1352 | 3178 | 1325 | 18 | 2270 | 908 | 245 | 1790 | 11086 |
| BIZANOS | 401 | 1337 | 578 | 0 | 622 | 446 | 132 | 534 | 4050 |
| GAN | 406 | 1415 | 450 | 36 | 658 | 393 | 209 | 778 | 4345 |
| GELOS | 293 | 921 | 491 | 20 | 498 | 246 | 127 | 483 | 3079 |
| IDRON | 193 | 763 | 587 | 4 | 436 | 507 | 159 | 554 | 3203 |
| JURANCON | 755 | 1761 | 900 | 16 | 932 | 428 | 183 | 940 | 5915 |
| LEE | 70 | 199 | 172 | 4 | 98 | 172 | 43 | 183 | 941 |
| LESCAR | 925 | 1920 | 1408 | 21 | 1222 | 965 | 310 | 1342 | 8113 |
| LONS | 1028 | 2615 | 1604 | 37 | 1866 | 992 | 319 | 1646 | 10107 |
| MAZERES-LEZONS | 183 | 597 | 230 | 8 | 286 | 98 | 15 | 226 | 1643 |
| OUSSE | 79 | 253 | 223 | 9 | 196 | 175 | 57 | 214 | 1206 |
| PAU | 7087 | 19014 | 16149 | 35 | 11137 | 6083 | 1724 | 8991 | 70220 |
| SENDETS | 53 | 207 | 65 | 12 | 118 | 61 | 28 | 126 | 670 |
| CAPP | 12897 | 34364 | 24262 | 244 | 20479 | 11514 | 3571 | 17971 | 125302 |
Construction du graphique :
fig = plt.figure(figsize=(18, 10))
fig.suptitle("Catégories socio-professionnelles de la CAPP en 2010\nPau et Billère", fontsize=20, color="#444444")
width = .3
# color scale
colors = ["#F4A460", '#E24A33', '#348ABD', '#988ED5', '#777777', '#FBC15E', '#8EBA42', '#FFB5B8']
# PAU et CAPP
ax1 = fig.add_subplot(121, aspect="equal")
pau_pie = ax1.pie(
# data
df_cat.loc["PAU"].drop("total"),
# wedges
colors=colors,
radius=1,
wedgeprops={"width": width, "linewidth": 1},
# labels
autopct="%4.1f%%",
pctdistance=.85
)
capp_pie = ax1.pie(
df_cat.loc["CAPP"].drop("total"),
colors=colors,
radius=1 - width,
wedgeprops={"width": width, "linewidth": 1},
autopct="%4.1f%%",
pctdistance=.75
)
ax1.set_title("Pau", fontsize=18, color="#555555")
ax1.text(.1, -.1, "CAPP", fontsize=18, color='#555555')
ax1.text(.8, -.7, "Pau", size=18, color='#555555')
# Billere et CAPP
ax2 = fig.add_subplot(122, aspect="equal")
bill_pie = ax2.pie(
df_cat.loc["BILLERE"].drop("total"),
colors=colors,
radius=1,
wedgeprops={"width": width, "linewidth": 1},
autopct="%4.1f%%",
pctdistance=.85
)
capp_pie = ax2.pie(
df_cat.loc["CAPP"].drop("total"),
colors=colors,
radius=1 - width,
wedgeprops={"width": width, "linewidth": 1},
autopct="%4.1f%%",
pctdistance=.75
)
ax2.set_title("Billère", fontsize=18, color="#555555")
ax2.text(.1, -.1, "CAPP", size=18, color='#555555')
ax2.text(.8, -.7, "Billère", size=18, color='#555555')
# legende
fig.legend(pau_pie[0], df_cat.columns.values, fontsize=16)
fig.subplots_adjust(wspace=0)
fig.savefig("capp_pie.png", dpi=300)